四足强化学习项目测试记录
详细记录请见项目心得
Agile But Safe: Learning Collision-Free High-Speed Legged Locomotion
项目地址:https://github.com/LeCAR-Lab/ABS
环境配置(按照项目的Readme.md来配置)
创建conda环境,安装torch
安装Issac Gym建议按照https://zhuanlan.zhihu.com/p/618778210去配置
问题
安装方式过时
使用 pip install –use-pep517 .
依赖缺少
使用 pip install pygments
克隆仓库,安装rsl_rl框架以及legged_gym
训练policy,并使用tensorboard(Ctrl+V或者在命令里面加入–headless可以关掉Isaacgym的渲染,加快训练)
- Agile policy
在代码里面加了一个log地址的print,在终端执行命令之后,会有一个tensorboard地址的输出,按照输出的地址去启动一个tensordoard(我是因为6006端口被占用,所以需要指明端口6007,否则默认6006),在去对应网址上查看就好。

根据数据反馈,迭代次数在600左右就已经趋于稳定,没有必要迭代4000次。 - Recovery policy
只要前面没问题,这里大概率没有问题
问题
Agile policy
无法找到gymtorch.cpp(Issac Gym里面的)
同时开vscode和tensorboard,tensorboard会把浏览器卡闪退
最好浏览器少开界面,关掉其他应用
- Agile policy
训练RAnetwork(没有tensorboard,待加入)
- 训练
testbed.py的line289决定迭代次数?不是很确定
之后按照readme的指导做就可以
- 训练
项目概述
项目框架
基于legged_gym和rsl_rl。
legged_gym负责提供强化学习的整体框架,从环境创建,智能体创建到训练过程。
rsl_rl负责提供强化学习的算法,如PPO,A-C network。
项目结构
大体工作流程是:ray-prediction network获取深度信息,和自身的状态信息一起给RA network,之后RA负责决定使用哪一个policy。如果没有障碍就用agile去加速,需要紧急避障的时候切换recovery去避障
- Policy (约束,奖励不同的PPO网络)
- Agile policy 负责快速到达目的地
- Recovery policy 负责在短暂时间内避开障碍,此时自身速度较快
- Reach-Avoid network 根据自身(姿态,电机位置等信息)和外界环境(深度图获取的二维地势)的状态感知来决定执行哪一种policy
- ray-prediction network (仿真时不需要) 实际部署时将深度图转为二维平面信息的网络
项目评估
Agile policy训练阶段
在700次(30分钟以内)的迭代过程中,agile policy就达到了不错的收敛性
Recovery policy训练阶段
和agile policy效果相似,收敛性不错,但是前期训练速度比agile policy慢好多,应该是训练目的不同
RA network(项目重点)
训练过程没有记录,只记录网络评估结果。
结果分析:
成功率74%,超时率14%,平均速度1.36m/s,轨迹跟踪速度(agile policy)2.78m/s
RA触发率 65%,触发RA之后的成功率83%
触发RA之后的碰撞概率44%,没有触发RA的碰撞概率55%
结合论文数据,成功率(85%),超时率(11%),平均速度(1.87)有差别但是并不大。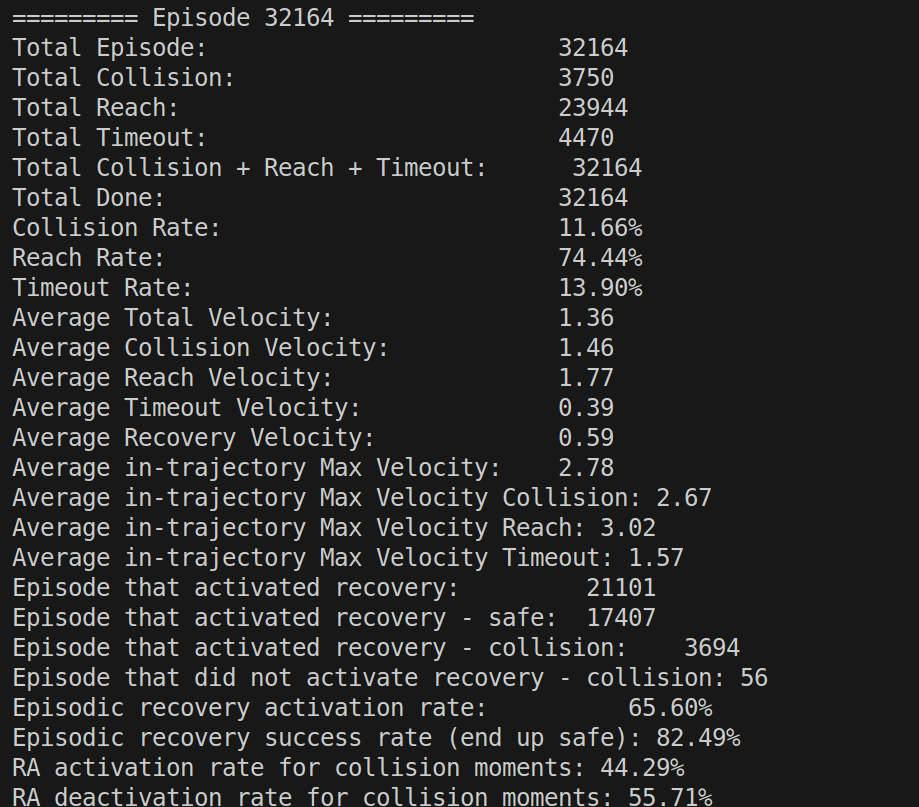
评价
- 侧重点在于高速且安全的导航算法,避障主要是躲避面前较大的障碍物,没有过多提及对于复杂地形的适应性。
- 两个policy是分开的两组PPO的Policy,二次开发可以借鉴
- RA的加入就是选择执行哪一个策略